Tue, 24 Jul 2007
A quick intro to the Mugshot data model [14:21]
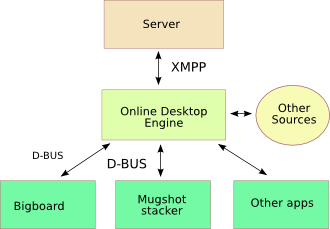
One thing I've been working on over the last few months is creating a flexible
way for software running within the online
desktop to retrieve information from the server. I've been calling this the
"data model"; it's not a single piece of software, but rather a set of concepts,
protocols, and software components that all fit together.
I posted an extended
design document for the data model to the Mugshot mailing list before
starting work on it. This post isn't meant to be a substitute for that,
or for a reference manual, but just to give a little taste of what the data
model is about.
The basic concepts in the data model are resources and property.
A resource represents some thing: a user, an application, an addressbook entry.
It is identified by an URI like http://mugshot.org/o/user/61m76k3hGbRRFS
(the resource for my user account on mugshot.org). A resource has properties,
which are just values identified by names; a Mugshot user resource has properties
called name, photoUrl, contacts, and so forth.
(Yes, the name "resource" is borrowed from RDF.)
You get information about resources by making queries. A query is a bit like a HTTP
GET; you send a query name and a list of parameters to the server, and get
a list of resources as a result. Just getting a list of resource URIs isn't
that interesting, so you can also specify a "fetch string" with the query
which says what property values to retrieve for each resource. If the property values
point to additional resources, you can recursively specify what properties to
retrieve from those resources. The most basic query is the 'getResource' query,
which just gets property values from a single resource specified by its ID. For example,
if you wanted to get my name and "home URL" from the mugshot.org server, and then
also get the name and homeUrl for everybody in my contact list (my network), you
could use the query:
http://mugshot.org/p/system/getResource
resourceId: http://mugshot.org/o/user/61m76k3hGbRRFS
fetch: name;homeUrl;contacts [name;homeUrl]
The result from that is a list of resources and their properties; some of
which are "direct" (query results), and some "indirect" (resources referenced
by other resource properties)
http://mugshot.org/o/user/hKcbRMYl4vNDqw (indirect)
name: Colin
homeUrl: http://mugshot.org/person?who=hKcbRMYl4vNDqw
http://mugshot.org/o/user/gDmfAh8d7gXVRP (indirect)
name: Havoc
homeUrl: http://mugshot.org/person?who=gDmfAh8d7gXVRP
http://mugshot.org/o/user/61m76k3hGbRRFS (direct)
name: Owen
homeUrl: http://mugshot.org/person?who=61m76k3hGbRRFS
contacts: http://mugshot.org/o/user/gDmfAh8d7gXVRP
contacts: http://mugshot.org/o/user/hKcbRMYl4vNDqw
The thing that goes a beyond a HTTP GET is that a query doesn't just fetch
property values, it also selects for future notification on those properties.
So if Havoc changes his name on the server, I get notified immediately. This
is important for the online desktop where there is no reload button and the
user will expect information to just update by itself. Since the server tracks
what it has sent the client, it can also avoid sending the same data
over and over again.
I don't want to go into a lot of detail here about how the protocol works, how
you add properties to the data model in the server, or how you access the
data model from client code, so I'll just leave things here with a picture
and a couple of code snippets. The picture:
Complete server code necessary to add the homeUrl property:
@DMProperty(defaultInclude=true, type=PropertyType.URL)
public String getHomeUrl() {
return "/person?who=" + user.getId();
}
Client code in python for retrieving data from the model via the online desktop engine:
def on_got_self(resource):
print resource.name, resource, resource.homeUrl
for contact in resource.contacts:
print " ", contact.name, contact.homeUrl
model = DataModel()
query = model.query_resource(model.self_id, "name;homeUrl;contacts [name;homeUrl]")
query.add_handler(on_got_self)
query.execute()
Fri, 20 Jul 2007
Widget skeletons, GPU theming [12:42]
I agree 100% with Tim
that using OpenGL directly as a rendering API for GTK+ makes no sense. The OpenGL 2D API is outdated
and irrelevant; using the 3D API for acceleration of 2D is possible, but involves a lot of deep
hackery; you want something like glitz
to hide the details.
But does that mean there is no use for 3D rendering engines in the GTK+ world? I don't think that's
the case. One idea I've been thinking about recently is that a 3D engine could provide a way of
doing flexible theming in a way that is more accomodating of custom widgets than pixmap-based
approaches. With a pixmap-based approach, if you know how to theme a button, that doesn't tell
you how to to theme something that is somewhat like a button. For example, imagine that
you had a button separated into two parts with a shallow groove in between, similar to what
you often see for a drop-down on a browser's back button.
A theme that knows how to draw a button won't know how to draw a button with a groove. But if
the custom widget calls the theme API not as "draw a button", but as "draw a button with this skeleton",
where the skeleton is a two-and-a-half dimension shape like:

Then the theme can apply textures, pixel shaders, and possibly transformations to the shape to get the
final appearance. The same approach that produces a button from the basic box shape should
produce something reasonable from the custom skeleton.

(A poor quality mockup in the GIMP.) Note that with pixel shaders, you
aren't restricted to pure 3D looks; it should be possible to get a
flat high-contrast appearances if you want that. Another possible
point of control for the theme engine would be modifying the skeleton
a bit by, say, rounding off the corners.
This approach should allow a very wide range of themes; what it doesn't allow easily
is themes that reproduce anything that a graphics designer could possibly dream up
and draw in the GIMP or Photoshop. So, it would be very important to have interactive
user-friendly tools for theming that allow the graphics designer to play around,
get a sense of the possibilities and create themes without having to go through the
intermediatary of a programmer.
Wed, 04 Apr 2007
Gimme, Bigboard, etc. [10:49]
Alex : I just
wanted to quickly respond here to the points that you raise. First,
Bigboard is not some huge skunkworks project; it's a prototype with
slightly more than one person working on it for slightly more than one
month, with all the source code in an open repository. And before we
put any code down, we showed mockups and talked about our ideas at Fudcon.
But it's the fact that it is a prototype -- a place for us to try out our
ideas, see what they look like on the screen live, and show them to
others -- is why even now it's premature to worry too much about how
it relates to Gimme. We didn't feel comfortable going to you and asking
you to take let us take Gimme, require users to have an account on an unstable
web service, add a hard dependency on a unstable custom canvas library,
and redo the user interface to use these dependencies, in the
process stripping away most of the polish you've added to Gimme. Maybe
you'd have agreed, but I wouldn't have, if it was my project!
A common library for writing panel-like objects in Python and
GTK+ would be possible, but I really don't see a big value there. It's
not a lot of code and adding a common dependency would mostly be
another hurdle to users trying Gimme or Bigboard out. The
goal here isn't to have the minimal number of lines of code, beautiful architectural
diagrams, and a coherent story about how things fit together from the
start. Let's get the ideas out, see what works, what doesn't work, and
where we we want to go. The architectural diagrams can be added later.
And because Gimme and Bigboard are both written in Python and GTK+,
if the consensus ends up being that Bigboard isn't total crack, taking
the good parts of Bigboard and integrating them into Gimme won't be
a big deal.
Fri, 29 Sep 2006
Element identity and structured data in XML [10:18]
Like most people, my first experience with XML was with document
formats: XHTML, SVG and so forth. So I've always had the idea that
an XML element represents some sort of platonic ideal object: if
you have an HTML anchor element or a SVG path element, it's well
defined what it means, and what the content model is. But documents
aren't the only use for XML. For
mugshot, we pass lots of
structured data between the server and client via XMPP, and between
the server and AJAX web pages. And we often have things like:
<user userId="abcd12abcd" name="John Doe">
<currentTrack>
<artist>Johnny Cash</artist>
<song>I Still Miss Someone</song>
<playLink service="itunes" playlink="http://store.apple.com/..."/>
<playLink service="yahoomusic" playlink="http://music.yahoo.com/..."/>
</currentTrack>
<favoriteTrack>
<artist>The Beatles</artist>
<song>Here Comes the Sun</song>
<playLink service="itunes" playlink="http://store.apple.com/..."/>
</favoriteTrack>
</user>
There are two weird things about the above from the “platonic ideal”
perspective. First, the <currentTrack/> and <favoriteTrack/> elements don't
really have any meaning other than the relationship of their content
to the parent element. They are just “attribute” that happen to have
structured XML data. The second thing is that <currentTrack/> and
<favoriteTrack/> have the same structure, even though the element names
are different. You could try to fix up the second problem and use a
common element name:
<user userId="abcd12abcd" name="John Doe">
<currentTrack>
<track>
<artist>Johnny Cash</artist>
<song>I Still Miss Someone</song>
<playLink service="itunes" playlink="http://store.apple.com/..."/>
</track>
</currentTrack>
[...]
</user>
Or you could even try to fix both problems by using a generic
element to represent a "XML-valued" attribute:
<user userId="abcd12abcd" name="John Doe">
<attr name="currentTrack">
<track>
<artist>Johnny Cash</artist>
<song>I Still Miss Someone</song>
<playLink service="itunes" playlink="http://store.apple.com/..."/>
</track>
</attr>
[...]
</user>
Or we could split things up and actually use an attribute:
<track id="track1">
<artist>Johnny Cash</artist>
<song>I Still Miss Someone</song>
<playLink service="itunes" playlink="http://store.apple.com/..."/>
</track>
<user userId="abcd12abcd" name="John Doe" currentTrack="track1"/>
But I think all of those are essentially silly. The natural way to do
structured data in XML is just different than a document use. When you have
structured data: 1) some elements only have a local meaning in the
context of their parent element. 2) there is a concept of “type” which
is distinct from element identity.
Now, if there are any XML experts in the readership, they probably are
now thinking that the above is some combination of blindingly obvious,
woefully simplified, and hopelessly misguided. And they are doubtless
right. But I found it a useful clarification of my thinking around XML
design.
Sun, 18 Jun 2006
Just like Riding a Bike [19:50]
I've been putting the old saying "It's just like riding a bike, you
never forget" to the test this weekend, having avoided that particular
activity for the last 20 years. I'm considering buying a bike and
doing some riding as a more air-cooled form of summer exercise, so I
rented one this weekend to regain some basic ability. So far the
results have been mixed as to whether it's possible to forget how to
ride a bike: it only took me 45 minutes riding in circles around a
parking lot to regain some ability to balance, turn, and stop, but the
ground sure does seem further away than when I was twelve. Goal for
tomorrow morning: relax my death grip on the handlebars and hopefully
end up not feeling like I've been bench-pressing weights all day, as I
do right now.
Update: moderate success. I certainly feel less trashed this
evening than I did yesterday, after riding for somewhat longer
today. I even saw one person on the trail that I was probably more
skilled than. Of course, he was about 7 and using training wheels.
Mon, 12 Jun 2006
There are no harmless race conditions [11:01]
I spent most of Friday tracking down a problem we had been seeing with
the Mugshot Windows client for months, where important parts of the client (Mugshot.exe) would mysteriously vanish
from the system. This happened to both Bryan and Havoc when we pushed a new client release last week. Using information from that, combined with uninstalling
and installing things about 200 times, I was able to track the
problem down to the following sequence:
- When the upgrade starts, we tell the old client to exit
- The Windows Installer goes to remove the old version, and finds that Mugshot.exe is still in use, so it schedules a delete after the next reboot
- The old client actually finishes exiting.
- The Windows Installer installs the new files, and since Mugshot.exe is no longer in use, immediately replaces it with the new version, instead of scheduling that action to happen after reboot.
- The user is prompted to reboot the system, and after reboot, Mugshot.exe is deleted.
The fix, once tracked down, was pretty simple ... just actually wait
for the old client to finish exiting before proceeding. Now, I knew when
I originally wrote the code the race condition could happen, but convinced
myself that It Will Be Very Rare: the Windows installer has all sorts of
other work to do as well, and the client will exit quickly. And also
It Will Be Harmless: maybe the user will be told to reboot unnecessarily,
but that's all. As is almost always the case, neither was in fact true.
Other thing I should have known better about this weekend: when
attending an outdoor music
festival in the rain, waterproof footware will make the experience
vastly more enjoyable, even if the music is worth it.
Tue, 07 Mar 2006
Do they have sheep in Burma? [21:01]
Warning: the following is not for those overly squeamish about dietary fat,
nor for the ethnic cuisine purist.
I made the following stew on Sunday and have been feasting on the leftovers
for the last two nights. It has no actual connection to Burma (or Myanmar),
other than the combination of South and Southeast Asian flavors which
I believe to be characteristic of the country. The inspiration here, other
than the ingredients at hand, is the memory of the stews that one of the
other students in my dorm at the University of Chicago would cook in the
kitchen there. I don't know what part of Southeast Asia she was from —
almost certainly not Burma — and I never got up the courage to ask to
try on of the stews, but they always looked mysterious and smelled great.
The recipe should work as well with beef or even, I'd guess, goat. You
don't want a fine cut of meat for this: in the long cooking, the fat
and connective cookie dissolve and combine with the coconut milk into
an luxurious, even unctuous broth.
I served this over a Japanese medium-grain rice, but a Southeast-Asian
sticky rice, or even arborio would work as well. In fact, the combination
of the creamy broth with moist and slightly chewy rice is reminiscent
of risotto. I would avoid Basmati or Jasmine rice ... the broth should
coat the rice, not be absorbed by it.
"Burmese" Lamb Stew
1.5lbs bone-in lamb stew, cut in 2 inch chunks
1/3 cup canned coconut milk
1 tbsp fish sauce
1 small onion finely diced
2 medium potatoes, peeled and cut into 1 inch chunks
2 tsp fresh marjoram, finely chopped
2 tsp fresh ginger, cut into fine shreds
1 tsp ground coriander
1/2 tsp turmeric
1/4 tsp cayenne pepper
4 whole green cardamon pods
2 bay leafs
8 black peppercorns
Peanut oil
Brown the lamb on all sides in oil over medium-low heat in a
dutch oven or similar. Use multiple batches if necessary to
avoid overcrowding the pan. Remove lamb from pan and drain on
paper towels.
Refresh oil if needed, add onion, and cook over low heat until
the onion is soft and beginning to brown. Add ginger, whole and ground
dried spices and saute briefly until the spices are fragrant.
Add lamb and 3-4 cups water (enough to just cover the lamb), bring
to a boil, reduce heat, and simmer partially covered for 2 hours.
Add potatoes and fish sauce, cook for 20 more minutes until the
potatoes are cooked, add coconut milk, return to a simmer, taste
and add salt if the dish is insufficiently salty from the
fish sauce.
Serve over medium grain rice with a side salad of yogurt, cucumbers,
and finely chopped red onion. Makes 3 small but rib-sticking
portions.
Notes: All quantities above are approximate and from memory. The
lamb should be completely tender and coming off the bone, but the
potatoes should keep their shape. Don't eat the cardamon pods, bay
leaves, or peppercorns.
Sun, 11 Sep 2005
Seen while washing dishes [21:34]

Ice on a puddle? No, it's salt crystals I found this morning in the
bottom of my sphaghetti pot. A little bit of salty water had dried up
leaving these crystals behind. There's several interesting things
about the image to me: it demonstrates very well the idea of domains -
crystals started at various nucleation points and grew out and met
each other. It's also interesting to see different growth behaviors in
different parts of the pot, probably depending on drying rate and salt
concentration. In some areas you have long linear crystals; in other
areas the growth is more compact. Most of the crystals branch
at 90 degree angles, but a few grow in a more spidery pattern.
(Somewhat reminiscent of patterns you get in
diffusion limited aggregation simulations.)
Fri, 29 Apr 2005
GUADEC registration fee [10:07]
First let me say that I don't think anyone is entirely happy
with the registration fee situation. Obviously the
fact that payment is only by paypal is far from ideal.
I'm not completely in agreement with where the registration
levels were set. The website is confusing. But it's
not an attempt to rip people off or discourage people from
coming.
Let me explain the levels in a little more detail: there are
three levels:
Professional: 225EUR (+ 16% VAT == 261EUR). This rate
is for attending GUADEC as part of their job function.
Professional contributor: 150EUR (+ 16% VAT == 175EUR).
This rate is a discount offered to professionals (people
attending GUADEC as part of their job function) in various
classes of people who contribute to GUADEC and GNOME:
speakers, foundation members, employees of advisory board
companies, and members of 'bwcon' (a local technological
organization which is helping put on GUADEC.)
Student/hobbyist: 30EUR (+ 16% VAT = 35EUR). This level is
for people attending GUADEC for reasons unrelated to their
job.
We're not going to investigate who registers as a hobbyist. We want
all members of the GNOME community at GUADEC, so if paying the the
professional fee poses a problem for you in any way (moral, financial,
typographic), please register as a hobbyist.
So, why charge registration fees at all? The basic reason is that
plane tickets are expensive. While our sponsors largely cover costs
like the the venue, if we take in more money, we can bring in
more GNOME hackers from around the world. I think it's
very reasonable to ask people for who are coming to GUADEC as
part of their job to help bring to GUADEC those GNOME contributors
that don't have a company to sponsor them.
Thu, 07 Apr 2005
Cooking [23:42]
My cousin Alice from Germany has been staying me this week and
exploring Boston, and we've done quite a bit of cooking in
the evenings.
On Saturday we cooked Indian: a dish of tomatoes and masoor
daal (based on a recipe titled rasam, but it didn't come out
remotely like that, though it was tasty enough), potatos
and eggplant with fenugreek seeds, and rice with fresh
fenugreek leaves.
Monday, I made one of my favorite dishes ... a Southeast
Asian (quasi-Vietnamese) chicken soup with rice noodles.
It's all about the garnishes: we had bean sprouts, fresh
mint and coriander, sliced chiles, lime wedges, and
ginger paste.
Tuesday, we made a dish that Alice learned from her brother:
rigatoni with winter squash. You basically cook the squash until
it is soft, mash it with parmesan and black pepper, and then mix in
the cooked pasta. Very good and not at all something that I'd normally
make myself. We made it with buttercup squash which gave the whole
dish a slightly flourescent yellowish-green color. Apparently it is
even better when made with pumpkin.
On Wednesday we cooked cod with the remaining fresh fenugreek,
together with couscous with dried cranberries (something that I picked
up from Rosanna and Jonathan recently), and a relish of apple, minced
serrano peppers, mint, and lemon juice. A real treat and less than a
half hour of total preparation and cooking time.
Tonight we took leftover mashed squash from the pasta, and combined it
with leftover chicken stock from the soup on Monday night, cooked it
for a while with some pieces of star anise, then pureed it, and added
a bit of cream. Voila, winter squash soup. We had that with good
bread from Whole Foods and a cheese and bean sprout omelet.
All in all, it's been a fun and tasty week.
Fri, 03 Dec 2004
Pagers in Luminocity [14:37]
I've been spending some time again this week on Luminocity; mostly
redoing the texture handling code. With the rewrite, it can break
windows larger than the max allowed texture size into multiple tiles,
and I've also added mipmap support. After getting the mipmaps working,
I quickly hacked up live thumbnailing pagers:
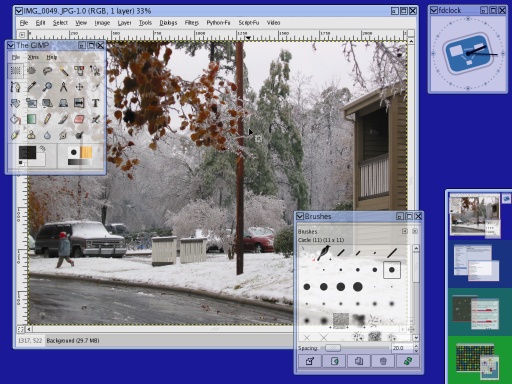
From a code perspective, that screenshot doesn't have 4 pagers. It's
5 pagers, one of which happens to be full screen. The effect is
similar to what Enlightenment and the GNOME pager had several years ago,
but the larger size, higher quality scaling, and immediate updates makes
it feel a lot nicer. That's a lot of screen real estate to take up
on the screen, of course; expanding the pager on mouseover might work nicely.
Sat, 20 Nov 2004
Rotated text in GTK+ and GDK [17:50]
Many years ago, when Microsoft first added TrueType support to Windows,
I remember being very impressed by a demo where a text string was rotated
and drawn in different colors. Simple stuff, really, but something that
we've never been able to do in GTK+ because of the limitations of the
ancient X drawing API. (Crude support was added for rotated glyphs for core
X fonts eventually, but who wants rotated, non-antialiased text? Can
you imagine anything more ugly?) A lot of the pieces have been falling
into place over the last few years: GTK+-2.4 required Xft and no
longer support core X fonts. Pango-1.6 added PangoMatrix and implemented
rotated rendering for the FT2 backend. Over the summer, I added
PangoRenderer to Pango, which abstracts out all the positioning,
attribute parsing, and so forth in rendering a PangoLayout, making
adding rotated rendering for additional backends a lot easier. What was left
was writing a PangoRenderer for GDK and some API to rotate GtkLabel.
I finally got around to that this week.
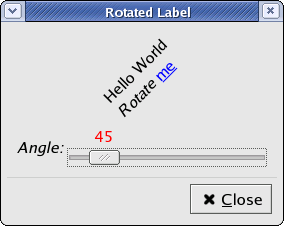

I've always been just a little confused by transformations when drawing;
if I want cairo_rectangle (cr, 0, 0, 1, 1) to drawn
a 50 by 50 square at 100 by 100, is that?
cairo_translate (cr, 100, 100);
cairo_scale (cr, 50, 50);
Or is it?
cairo_scale (cr, 50, 50);
cairo_translate (cr, 100, 100);
When I added PangoMatrix to Pango, I decided I was fed up by continually
having to try everything both ways, sat down, worked through various
examples, and really got it straight in my head. And because of that,
I got all the transformations used in the rotated text example above
right the first time. A new experience. So, what's the secret?
What helps me is to keep two distinct but equivalent formulations
in mind. (I'm talking in terms of Cairo here, but Cairo, Java2D,
gnome-print, Postscript, etc all borrowed Postscript's conventions, so
they are the same.) The first formulation defines how the matrices work.
The current transformation matrix gives the transformation from user
coordinates (the ones you pass to drawing functions) to device
coordinates (the ones that determine what pixels are drawn).
Mathematically:
p_device = M * p_user
When you call a Cairo transformation function, that gets added on the
user coordinate side. Mathematically:
p_device = M_orig * M_new * p_user
So, say we call cairo_translate (cr, 100, 100)
then cairo_scale (cr, 50, 50). We get a transformation
that first scales by 50 times in each direction, then translates by
100, 100. That formulation is good to have available, especially if you need
to handle the matrices directly (as when implementing bits
of Pango or Cairo.) And you can use to check to see which order
of the two I quoted is right by taking the point 1,1 and putting
it through the two transformations. But it's not entirely intuitive:
you have to think about the transformations in the reverse order
they appear in the code. For, writing code what I find easier
is:
When you call a Cairo transformation function, that scales/
rotates/translates the axes of the user space coordinate
system with respect to themselves.
With that formulation, in mind, it's easier to see that the order
we need is the first one. cairo_translate (cr, 100, 100)
shifts the coordinate origin to 100, 100.
cairo_scale (cr, 50, 50); then scales up the coordinate
axes by 50 times in each direction, leaving the coordinate
origin in the same place. (This all would be clearer with a
diagram...)
Now if I only could shake the feeling that by writing this I'm courting
a collision with a graphics system that uses the opposite convention...
Sat, 13 Nov 2004
Boot poster challenge [12:19]
When it comes to trying to speed up system startup, it often seems to
me that the work people do is based on blind guesses as to what the
actual bottlenecks are. What I've really wanted to see is a graphical
representation of the boot process along the lines of some of the
examples that Edward Tufte
uses. I've now written
this up in detail along with an offer to pay for the printing of a
hard copy if someone picks up the challenge.
Wed, 10 Nov 2004
Screenshot Update [20:16]
Here's an update of my Luminocity screenshot from a few weeks ago:
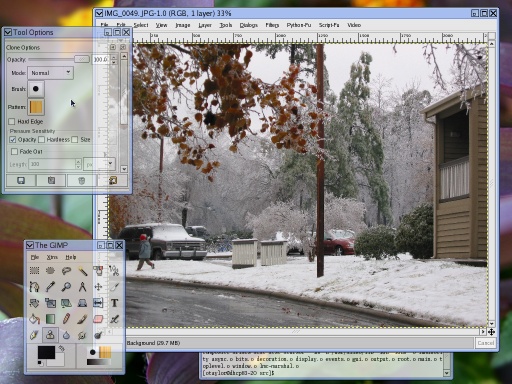
As you can see, the main difference is, as promised, window decorations.
What doesn't show up in the screenshot is just how nice resizing
with those decorations is. No flash, no flicker, no jitter, no redraws.
I could sit there for hours making windows bigger and smaller....
Fri, 05 Nov 2004
Texture profiling [16:19]
With the work I've been doing recently with luminocity, I realized
that I had absolutely no idea of what was going on for video card memory usage.
Rather than putting some one-off print
statements into the card driver, I decided to try and make something
a little more reusable and convenient. That Sunday-afternoon project
ended up taking most of this week, but I'm pretty happy with the
result: texturetop.
The obligatory screenshot:
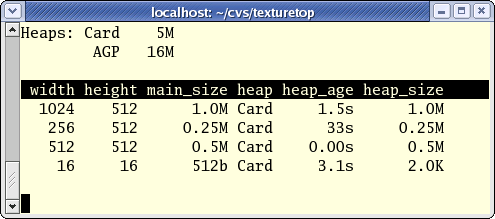
In order to have a decent chance of getting this
upstream and out of my hands, texturetop is a text-mode client. No
GTK+, no GLib. Actually, texturetop is just a minimal front end. The
somewhat larger piece of work was adding code to Mesa/DRI to get it to
connect to texturetop and provide the information. libGL and texturetop
talk a text-based protocol over a socket, so it was an opportunity
to dust off my “how to listen on a socket” skills as well as my “how
to write a linked list by hand” skills.
We have dozens of profiling tools on Linux, from oprofile and
valgrind, to memprof, xrestop, and texturetop. Is there some way that
a "profiling console" could be created that would provide access to
all this disparate information and integrate it together?
Tue, 02 Nov 2004
Virtual events [11:45]
One of the central objects in the
GLib main loop
is GSource. What is
GSource the source of? Events. But where are the events? There is no
event object, and the docs very seldom mention events (though they
do frequently talk about “event sources”.) What I realized last night
is that there really are events in the GLib main loop, they are just
virtual: a concept without an object behind it.
A lot of the GLib main loop becomes clearer when viewed in this light:
the return value of the ‘check’ and ‘prepare’ members of
GSourceFuncs
isn’t “TRUE if it is ready to be dispatched”, but rather “TRUE if
there are any pending events for this source”.
g_source_set_can_recurse()
actually sets whether the source
can have multiple outstanding events. Recursion becomes a whole lot
more conceptually simple: we’re simply pulling more events off the
event queue and processing them before we finish processing the last
one.
Of course, because I didn’t realize this when I created
the main loop interface in 1998, or when I revised it for
GLib-2.0 in 2000, there are some places where the match isn’t
exactly perfect. For example,
g_main_context_dispatch()
should dispatch only the single event at the front of the (virtual) event
queue: instead it dispatches one event from each GSource
that has pending events and who’s priority matches the priority
of the highest priority GSource that has pending events. (whew!)
Mon, 01 Nov 2004
Luminocity [19:18]
Over the last week or so, I've been working on a new toy,
a combination window manager and compositing manager with
GL output called 'luminocity'. Note the word toy: I have
no intention of ever worrying about all the edge cases
and broken legacy clients that you need in a real window
manager. I do, however, intend to add title bars.
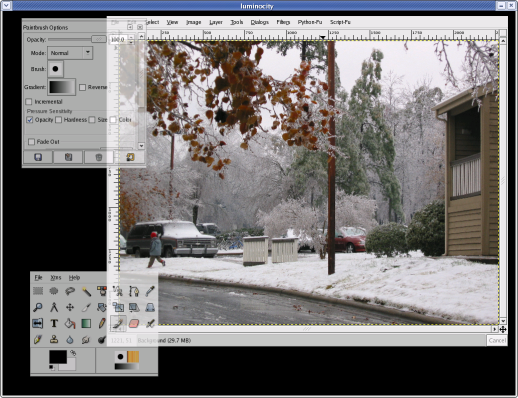
Despite the quick-hack nature of luminocity, I've had quite
a bit of fun with the code. It's nicely modularized with
lots of GObjects and signals. It has a separate rendering
thread for the GL output. There is some advanced Xlib
programming to keep everything async. And it uses
X extensions by the boatload: XFIXES, SYNC, DAMAGE, Composite,
XTEST. (And GLX, of course.)
The way that luminocity works is that you run luminocity
against an offscreen X display (I've been using the
kdrive based Xfake X server.) It asserts itself as the
window manger and compositing manager for the display and
pops up the output in a window. Input is forward back
from the window to the offscreen display. This makes
for a very cool development process. You run some apps
against the offscreen server. You start luminocity,
look at how the apps look. Play with them, move them
around. You quit luminocity, make some code changes,
restart luminocity. The apps are still there. It's a lot of fun.
What's next? Title bars. Some effects to take advantage
of GL - animations and live minimization. Some work
studying the performance bottlenecks. (Texture swapfests
seem to be a problem at the moment.) Maybe some work on
application synchronization. But in the end, the work
that Søren is doing on Metacity's CM is much more likely
to be the permanent way forward. Or maybe Looking Glass.
Luminocity has about the same architecture as
Sun's Looking Glass, it's just much simpler and smaller, all
written in C, and I have no plans to add 3D client support to it.
Mon, 06 Sep 2004
Building a tool [21:29]
I'm thinking on doing some more work on the FreeType font hinting
code sometime soon, so I've spent some time the last few weekends
building a program to view hinted outlines. The way that hinting
fonts for the screen works is that the outline is modified to
better fit the grid of pixels, then the modified outline is
scan-converted. My program allows looking at a magnified version
of the modified outline and comparing it to the resulting pixels.
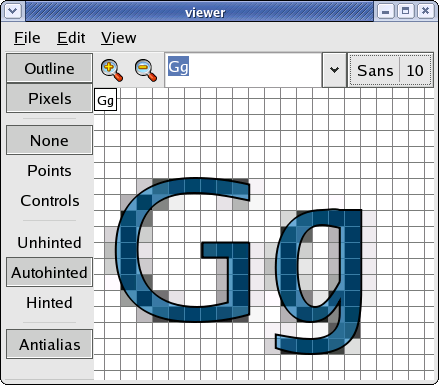
As you might guess from the spiffy, antialiased, alpha-blended
graphics, I'm using Cairo to do the main drawing. It's been a lot
of fun to write a very small, limited purpose application and
really nail the details. To list a few:
- The toplevel window automatically resizes as you zoom in
or out and change the text. But it respects the workarea
of your desktop and scrollbars appear when the contents
get bigger than that.
- The 1:1 image in the upper left is actually on overlay that
doesn't scroll with the contents. It can be dragged around
and if you drag it to an edge, it sticks to the edge
as the window resizes.
- The entire state of the application is saved to GConf,
so the next time you start it, it remembers your last
selected font, all the hinting and display options,
the text being used and so forth.
- The dropdown on the combo contains a history of the
10 last strings you've used, plus a set of fixed strings
in different scripts.
- You can save the output to a PNG image, and the output
is annotated with the selected font, the hinting style,
and the 1:1 image that normally appears in the overlay.
I was suprised by how well saving the entire application
state to GConf worked. There is no separation between preferences
and transient state. You can just exit the viewer at any time
and bring it up and it remembers where you were. This clearly
isn't the right model for most applications, but I wonder if
there are places in the GNOME desktop where idea could be
effectively applied; perhaps desk accessories like gcalctool,
gconf-editor, and gucharmap should work like that. For the
viewer, the code flow for interacting with GConf is a little
unusual; instead of monitoring GConf actively as the "model" of
the application, the viewer simply initializes from GConf on startup
and saves changes to GConf as they happen. This allows having
multiple viewers usefully running at once.
Sun, 08 Aug 2004
Sweet Corn [00:29]
One of the best benefits of being back up North is the ability to get
good, fresh sweet corn. Now, I need to say here that corn sold in a
supermarket is almost certainly not fresh. Corn that wasn't picked the
same day you eat it is not fresh. If you have ever ordered an item
that comes with "corn on the cob" in a restaurant in January, that's a
good sign that you have no idea what real corn tastes like. With that
definition out of the way, I never was able to find a single decent
ear of corn in the 6 years I lived in North Carolina. The few times
I actually found local corn at a farmer's market or farm stand
it was a poor, undergrown, worm-eaten approximation of the real
thing. I don't know if the problem down there was climate, soil, or
culture. But no problem here in Massachusetts so far.
So, how do you cook and eat corn? You husk it, drop it in boiling
water for as short as time as possible (5-6 minutes is about right),
butter it, salt it, and as soon as you can pick up the ear without
burning yourself, dive in. I take no position on eating pattern;
linear, spiral, and random access all work.
Corn goes well with other summer flavors. Tomatoes, fresh basil,
grilled meats, and so forth. In fact, fresh corn and fresh tomatoes,
with nothing but butter and salt for the corn and salt for the
tomatoes is a meal fit for a king. I haven't seen good tomatoes yet
this year, but I've had good luck the last few weeks with other
accompaniments. Last Saturday, in celebration of the beginning of
corn season, I had broiled lamb chops with a peach-habeñero salsa.
(slightly green peach, onion, finely chopped habeñero, red wine
vinegar). This week, I made a Thai-inspired sautée of scallops with
basil, garlic, fish sauce, and strips of chili. Both were easy to
make, really tasty. Both went well with the corn. In the end analysis
I probably preferred the scallops because they distracted less from
the corn. Which, after all, was the real point of the meal. Most
things you can cook 52 weeks a year these days. Corn season is 6 weeks
a year, if you are lucky. Or 6 weeks after 6 years if you've been
living down south.