Table of Contents
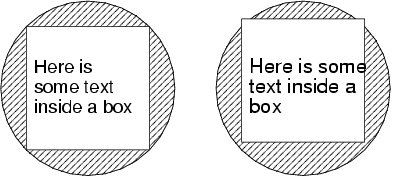
A frequent concept in graphics is that of a metafile. We record a series of drawing commands into a file or into memory, then then can replay those commands to different output devices: to a the screen, to the printer, and get the same output. Of course, the output won't be exactly the same. If we are rendering at a different resolution, on a device with a different range of possible colors, and so forth, then the results will look different. But there is a general idea of what “the same” is. If two elements lined up on one device, they should line up on another device. If a paragraph is inside a box on one device, it shouldn't run outside the box on another device. If a file fits on two pages on one device, it shouldn't run onto three pages on another.

For graphics, keeping the output sufficiently the same isn't hard; we just round all coordinates to the output pixel. We might have the occasional defect - two boxes that exactly butt against each other on one device might end up with a pixel of space between them on another device, but generally if we define our graphics primitives right, use carefully selected input coordinates, and round carefully, then things will come out pretty well. In any case, we'll never have more than a pixel or so of error in the output. Text, however, is more of a problem. Text is small: the dimensions of a character are frequently 5-10 pixels. Errors when rounding to grid coordinates are proportionally much bigger. Text is regular: if spacing is not uniform, if we have one pixel too much in one place, one pixel too little in another, this can be very obvious And finally, text layout is non-linear when we start wrapping lines; if one character gets a single pixel wider, that can push a word onto the next line, and a line onto the next page.
In this discussion, we need to distinguish between two different forms of metrics. Linear metrics are the metrics that the designer picked for the font, scaled to the particular output size. We'll consider these metrics to be stored with subpixel accuracy, either as fixed or floating point numbers.
Device metrics are the metrics adjusted to a particular grid. This adjustment has two parts; the outlines of the glyph are adjusted in the hinting process to conform to the pixel grid. Also, we need to quantize the overall width of the glyph with its surrounding left side-bearing and right side-bearing to an integer value.

The simplest way of storing text into a metafile is to just store the strings that are converted into text in the metafile, and reconvert from text to glyphs when replaying the metafile. The problem is that the size of the text and the line breaks will be different at different resolutions. When the code creating the metafile puts several pieces of text onto a page or combines text and graphics, they won't line up right. What the user sees in the print preview won't be what they see in the printed output.
The other problem with this approach is that we need to duplicate the layout algorithm when playing the metafile. But the layout algorithm might well depend on application specific information that won't be in the metafile. We can't use the same layout algorithm for a word-processor and a web browser.
The other extreme is that store the full output of the layout algorithm in the metafile; we compute the exact location of every glyph using linear metrics and store that in the metafile. Given that information, we have a couple of options when replaying the metafile. We could ignore the grid-fitting process and render unhinted glyphs at those exact locations. This requires more computational power than rendering grid fitted text, since we have to be able to display each glyph in many different positions - we can't just cache a single image of each glyph. But the worse problem is appearance; text rendered in this fashion looks blurry because of the lack of hinting.

So, a different approach is that for each glyph we pick the closest grid position and render the glyph there. This works reasonably well, especially at high resolution. The overall layout of the text matches the original with linear layout, but each glyph image is sharp. The main problem is spacing between glyphs; when we round to integer grid positions, sometimes we'll get 1 pixel too little space between too glyphs, sometimes we'll get 1 pixel too much. At small sizes, this can be very noticable.
When we have more sophisticated layout algorithms, then we have additional problems. The GPOS table in OpenType fonts allows positioning one glyph with respect to a particular point in a different glyph [OpenType]; if we do this positioning before hinting with linear metrics then hint and align to device metrics, the two glyphs may not line up properly in the output.
So, we need some sort of hybrid approach. At a high level, we need to reuse the layout that we did with linear metrics when creating the metafile. We don't want to have to recreate line breaks and we want to get exactly the same overall size for the text as when we started. We even want to keep individual words in the same place so that graphics line up properly. But in detail, we want to use the device metrics for inter-character spacing, and if we are using fancy positioning like GPOS tables, we want to do those with respect to the device metrics too.
In order to make the discussion more concrete, I'll briefly the Pango layout process. The Pango layout process consists of the following steps:
Divide the text into segments with the same font, direction (left-to-right or right-to-left) and shaping module. Each shaping module handles a different script, and they are selected based on Unicode ranges. These segments, called runs are the basic unit of the shaping run.
Convert the text in each run into glyphs by calling pango_shape().
Break the text into lines. When this involves breaking inside a single run, after the run is divided, pango_shape() is again called on each piece.
Reorder the runs on each line from logical order into visual order based on their direction.
The important thing to notice here is that the conversion from characters to glyphs occurs entirely within individual runs; if we have the position, font and text for each run, then we can recreate the full layout. We don't have worry about the details of how lines where broken, whether we're flowing the text around embedded images, and all the other details that may have gone into the processes of text layout.
So, the basic unit we want to store into our metafile our the runs of text. But this isn't a full solution, since when we reshape a run with device metrics, it won't have the same size as it did before. It may run past the line boundaries or overlap with other runs. Furthermore, we don't just want to reproduce the boundaries of the overall run, we want to get all the words and glyphs inside the run as close to their original position as possible, so if we have other graphics aligned with the text it still lines up properly.
To address this, we store in the metafile both the text of the run and the glyphs of the run as they were positioned when we were originally doing the text layout. (Alternatively, we can just store the text of the run, then do another shaping pass with linear metrics to recreate the original glyph positions.) Then, after we lay out the text with device metrics, we adjust the resulting positions so that they are as close as possible to the original positions.

This adjustment process is very similar in detail to the process of justification (which was left out of the description of the Pango layout process for simplicity, and also because it is a not-yet-implemented feature). In both cases, we need to know where in the line is best to insert space (between words, say) and where in the line we should avoid inserting space (between two connected characters, say). This is information that we need to compute in the shaping process and store with the glyphs.
There are two main practical differences between adjustment for grid-fitting and justification. First, we might need to shrink the amount of space within a run as well as grow the amount of space, something that we generally don't need to worry about for justification. (More sophisticated justification algorithms may have a natural width for each line which is slightly greater than the minimum width, but conceptually we still are expanding from that minimum width.) The problem with shrinking the amount of space in a run is that there might simply not be any more space we can take out of the blank space in the run (or there might not be any blank space in a run; consider a single word in a different font from the rest of the line.) So, if worst comes to worst, we might have remove space between characters. But we know we can always do as well as the "closest grid position" algorithm described in the introduction, and we may be able to remove space in a more intelligent way.
While the need to shrink works against us, the second difference works in our favor: we expect the total difference that we might to expand to be limited to just a few pixels in most cases. So, some of the sublities of justification aren't needed. For example, leaving large amount of white space inside a line of Arabic text is considered very bad typographic form, and instead kashida glyphs are inserted inside words to extend the cursive line. But if we only need to add a few pixels here and there to the line, then we can simply use whitespace between the words of the text.
To summarize a simple form of the above algorithm:
Start with a run of text and the positions of the glyphs in the run according to linear text.
Lay out the run again using device metrics, obtaining a new set of glyph positions.
Iterate over sections of glyphs in the text separated by whitespace. For each segment adjust the whitespace on either side to keep the segment centered as close as possible to it's original linear position. But never reduce any sequence of whitespace to less than half its original width.
If because of lack of sufficient whitespace, the overall length of the string doesn't match it's original length, redo the entire string by using the nearest grid position to the linearly-positioned characters for each character. (Or, in a more sophisticated variation, only do this to the segments where the deviation couldn't be sufficiently reduced by adjusting whitespace.)
If you implement the above algorithm, you discover that at small point sizes, the required adjustments to inter-word space are quite large. It's quite common that we end up in a case where either we can't make the full adjustment, or, if we do make the full adjustment, then the interword spaces are too small to properly separate the words. In this section, we'll introduce a technique that can significantly the amount we need to adjust inter-word spaces and also improve the appearance of the text. The approach in this section was partly inspired by David Chester's description of similar techniques on the FreeType mailing list [Chester].
Figure 9. Letter sequence ‘epo’ with device metrics. Note that both the right and left sidebearings increase between ‘e’ and ‘p’ and both decrease between ‘p’ and ‘o’

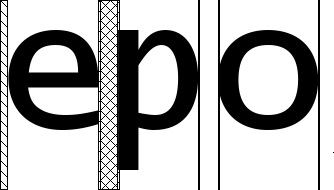
In non-cursive fonts, each glyph logically has an outline, and then space on either side of that outline - the left bearing and right bearing. When we hint the outline and quantize the width of the font to an integer value, then we introduce an error into each bearing; anywhere from -0.5 to 0.5 pixels. When we place the two glyphs next to each other, the errors might cancel, but they might also add up, so we might have anywhere from -1 to 1 pixels of error in the space between the two glyphs. In the case where the cumulative error is greater than 0.5 pixels in either direction, then we can reduce the total error by introducing or removing a pixel of space into the positioning.
It should be noted that this technique does not depend on the techniques described in the previous section; we aren't limited to applying it when we are laying out text in a device independent fashion; it can profitably used anytime we are setting text at a low resolution to improve the fit of the output.
Another interesting possibility to note is that if we fail at adjusting word space within a run and need to adjust letter spacing, then we can use the errors to figure out better places to adjust letter spacing. If we need to make a run 1 pixel longer, it's much better to add that extra pixel between two glyphs that are 0.4 pixels too close rather than between two glyphs that are 0.4 pixels too far apart. In one case, we've increased the spacing error by only 0.2 pixels, in the other case we've increased it by a full pixel
The above discussion applies most directly to Western scripts; Latin, Greek, and Cyrillic. When we look at East Asian scripts Indic, or Arabic scripts, some additional considerations apply.

For East Asian scripts, layout is traditionally done on a grid; each character takes up the same amount of space. When you have a segment of proportionally spaced script embedded, it is centered within a set of grid cells and then the grid resumes after the interruption. Also, East Asian scripts typically are written without word spaces. In such cases, there is no meaningful concept of putting extra space at some points in the line and not at others. Placing each character as close as possible to its linear position is the best we can do.
We should also note here that the problems of non-linear scaling are much worse for fixed-width fonts, whether they are East Asian fonts, or Western fixed-width fonts. The problem is that for such fonts the error for each character is the same, so rather than cancelling out, the errors add up over the whole line. If the average error per character is e, then for a proportional width font, we expect a total deviation for a line of length of e*sqrt(N) while for a fixed width font, the error is e*N.
The main interesting characteristic of Indic text from the point of view of our current discussion is the complex interaction of the different characters within a syllable. The basic unit of these scripts is the syllable, so if we have to make inter-letter adjustments, all points in a word are definitely not created equal; it's much better to make adjustments between syllables than within syllables.
Figure 12. Urdu in Nashtaliq font, with subpixel alignment (top) and linear positioning of grid fit characters (bottom)
![]()

Arabic text at first glance looks like a hard case; because each glyph joins onto the next, we might fear that any error at all between adjacent glyphs would cause unsightly gaps or improper joining. But Arabic fonts, as it turns out, are designed so that each glyph joins to the next with a horizontal segment at a fixed height, and with overlap in these segments. So, at anything but extremely small sizes; a small error in inter-glyph spacing won't upset the joining.
Even when we have more complicated types of joining, the fluid nature of Arabic makes it more foregiving of a bit of sloppiness. Figure 12 shows text in the Nashtaliq style of arabic, which has cursive attachment along a sloping baseline, which is achieved with positioning via the GPOS OpenType table. Even with the two-dimensional positioning that is involved here, there are barely any noticeable positioning problems if we take the simplest of approach of positioning device-fit characters at the nearest grid position.
We've seen that if we want to have the same line breaks and overall size for text at different resolutions, then for optimal appearance we need to take a sophisticated approach to text layout which merges the positioning that we get with unhinted, linearly scaled metrics, with the specific grid-fit metrics of the characters at the output resolutio. The implication of this is that metafiles can't be objects that know only about graphics primitives and absolutely positioned glyhs, but must be part of an API that that knows about both rasterization and at least the lower levels of text layout.
To implement the strategies described here, the text layout engine needs to be able to get a range of information from the font rasterization and graphics rendering systems. It needs to be able to find out both linear and device metrics. It needs to know when the output resolution changes so that it can redo text layout as necessary. And when implementing grid-fit kerning, it needs to be able to find out the errors in the side-bearings that were introduced in the hinting and grid-fitting processes.
Displaying graphics and text at different zoom factors, and on different devices is an extremely common operation, and when text gets involved, has traditionally been one where the user is frequently unpleasantly surprised. The techniques described here should allow users to be blissfully ignorant of all the traps of scaling text.
[Chester] Chester, David. Re: Hinting metrics.
[OpenType] . OpenType specification version 1.4.
A. Notes on figures
All figures other than Figure 1 are rendered using FreeType version 2.1.4 and a modified version of the Pango layout library.
- Figure 2, Figure 3
The font is Luxi Sans by Bigelow & Holmes, in Type1 format, rendered at 16 pixels using the FreeType autohinter.
- Figure 4 – Figure 7
Again the font is Luxi Sans rendered using the FreeType autohinter. This time the size is 10 pixels. The text is an extra from Benjamin Franklin's autobiography, from Project Gutenburg.
- Figure 8 – Figure 10
As in the previous series, the font is autohinted Luxi Sans at 10 pixels.
- Figure 11
The font is Microsoft MS Mincho at 21 pixels, rendered using TrueType bytecode hinting. The text is an excerpt from the README file of the Canna input method server.
- Figure 12
The font here is Nafees Nastal’eeq. The text is the first couplet of a Ghazal from http://www.arbornet.org/~tabish/u-font/